
All Models Fade - The Inevitability of Change
Part 2/n on what drift is, why it matters, and how we can start monitoring it.

In the first part of this mini-series (kicked off by my guest post for the
Substack inspired by Chad & Mark's new O'Reilly book on data contracts), I started listing high-level requirements that ML platforms need to meet with regards to data:Right Data, Right Time
Automated & Triggered Model Retraining
Proactive Data Drift Detection
Below, I give the long explanation (taking the scenic route) behind why all models eventually fade away.

(Note: In Part 01 of the mini-series, I first started talking about Tesla’s data engine. Recently
over at shared this interview with Kate Park that digs in deeper.)
The Inevitability Of Change
“Time is like a handful of sand - the tighter you grasp it, the faster it runs through your fingers.’ Henry David Thoreau
But why do models need to be retrained?
Why do they need to be retrained so frequently, especially in the case of real-time machine learning?
In fancy parlance, how does the inherent instability of data affect the performance and maintenance of ML models?
The Why of Proactive Data Drift Detection
Over time all models will start degrading in production.
In a really great
blog post, the number was 91% of ML models within a few years to a few months (based on a study from some okay universities like MIT, Harvard, Cambridge, & University of Monterey).
The question becomes more about how long it takes for the degradation to be unacceptable as opposed to whether it happens.
And the reason is because the data’s relevance degrades. Depending on the data’s inherent entropy, the data could degrade almost immediately (in milliseconds for really popular applications, gaming and IoT) or over decades (like a person’s Social Security Number).

And by degradation, we mean that the data being captured no longer accurately describes the current state of the corresponding person, behavior, or process and becomes less relevant.

Another term used to describe this growing dissociation between the data and its corresponding reality is “model drift”.
Two main types (and causes) of model drift are:
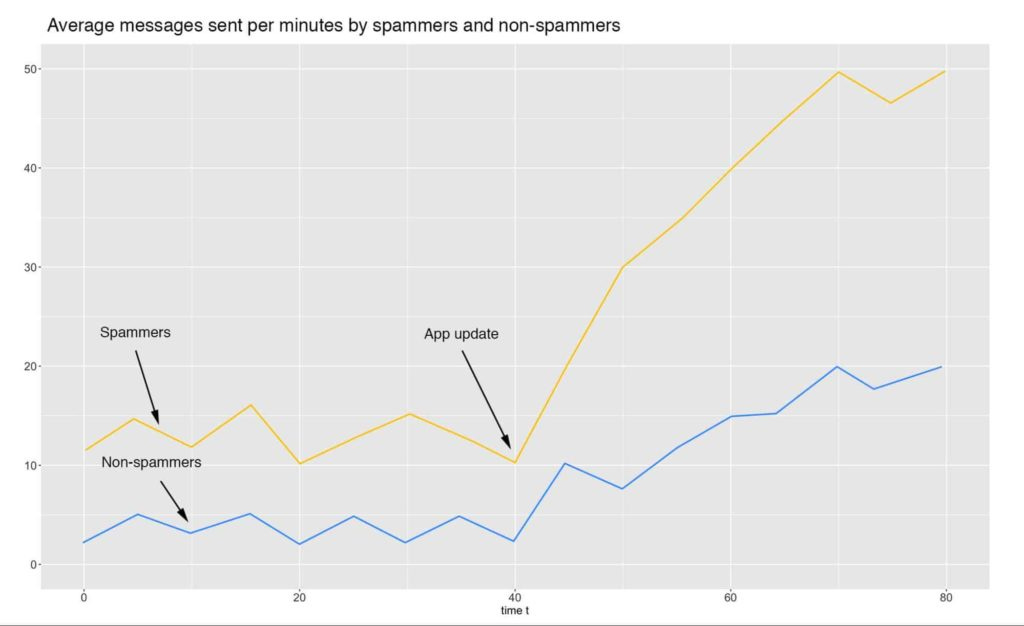
Concept Drift: The properties of the target have changed i.e. spammers used to send frequent emails that contained adult content or chain emails, now they send emails about bitcoin schemes.
Data Drift: The properties of the input features have changed i.e. spammers used to be the only ones that sent a ton of emails to many different users but changes in the email product have gamified using it (woohoo!) and now everyone is sending more emails.
Any company engaging in production ML for consumer facing applications and services must implement proactive data drift detection. The potential for harm is enormous with edge cases or low confidence predictions, especially in areas like autonomous vehicles where pedestrians have been harmed.

When all is said and done, Tesla addressed the need for proactive data drift detection as part of their data and ML platform operations. As data was streamed into their data collection and storage components, Tesla could ensure their data was as fresh as possible and data evaluation (as well as quality checks) were performed on a rolling basis and addressed in the datasets themselves.
So what do you do if you’re not Tesla? What’s the right level of data drift detection and management to pursue? What does it take to catch data drift? And how does it relate to data quality?
Managing Changing Data in ML
Combating Drift: Measure All the Things?
All forms of drift have the greatest impact after deployment, not training.
Technically speaking, drift is defined as “When the joint distribution of inputs & outputs at train time =/= joint distribution of inputs & outputs at test time” or P_train (X, Y) =/= P_test(X,Y).
The implication is that there are a number of ways performance of the function that was learned during training (off a specific snapshot of a dataset) can fall out of sync with the performance of the same function at test including:
Different Data Distribution: I.e. the data being used during production isn’t similar to the data used during training (and the premise of training an ML model is that data will be similar)
Changes in the Data Distribution: Maybe the data is from the same population but the population or set of behaviors is changing (ex: the change could be sudden, gradual, incremental, recurring)
Business logic & definition changes: Maybe the business logic has changed i.e. our understanding of what constitutes a spammer has changed and regular ole users are overall becoming heavier power users of the app, so now we need a different criteria.
There might not also be anything specifically wrong with the data and instead maybe we’re seeing more predictions of a certain kind of output because the model is doing exactly what it needs to be.
It’s hard to say which is why the second implication of the definition of drift is that it’s not enough to monitor how the model is doing; you need to also measure the inputs.
How To Measure & Monitor Data Changes
The key principle of thorough and comprehensive monitoring drift is you need to monitor the individual components of the equation (the data and the model) as well as the relationship of the data to itself (maybe in the form of features) and the features to the model.
There are roughly three main ways to measure drift (in order to start monitoring).
Calculating various summary feature statistics for statistical tests;
Using distance metrics, not just feature statistics;
Using drift detection algorithms to flag potential outliers and anomalies.
When calculating the summary statistics, etc there are wide variety of metrics that could be used to measure changes in model performance or in the data distribution including:
Changes in basic measures: True-Positive, True-Negative, False-Positive, False-Negative
Changes in model performance measures: Accuracy, Precision, Recall
Specialized metrics commonly used in drift detection: Kolmogorov-Smirnov (K-S) test, Population Stability Index, Page-Hinkley method, Kullback-Leibler divergence, Jenson-Shannon divergence, etc.
Drift detection is quite a bit easier when you have the ground truth label but there are plenty of cases (fraud, risk, massive economic upheaval, external situations like COVID-19) where ground truth is lagging or doesn’t exist.
In a perfect world, with a system that catches all the issues and when needed, you’d have monitoring for performance (at the services level), events (at the data and services level), alongside monitoring for explainability, outlier detection, and statistical monitoring.
If that already begins to sound a bit overwhelming, don’t worry, it can get worse.
Managing Drift
You (or ideally the system) has detected drift - now what? Your options are:
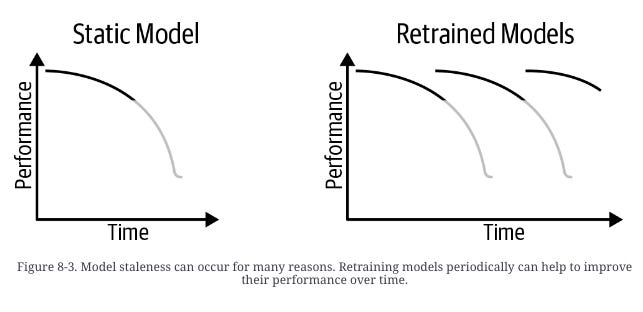
Retrain The Model(s)
The number one piece of advice: retrain your model.
Lookup data drift and that’ll be the top answer in every blog post, case study, etc. And there are a couple good reasons for the shotgun approach:
All models degrade in performance over time because of the inherent instability of data (see above) and it’s something that needs to be done anyway, so why not do it earlier?
Drift isn’t usually operating on a single feature alone – although the goal of feature engineering and selection is to ensure that features aren’t correlated or duplicative, it’s not a guarantee.
Feature Level Adaptation
Assuming you’re able to isolate a set of features that are de-stabilizing the model through drift, it might make sense to understand their relationship to the predictions and to each other, in order to determine whether you can drop the features and retrain the model.
Root Cause Analysis
The final answer (which should be the first strategy suggested) is some form of root cause analysis.
Besides understanding the nature of drift, why should you not blindly re-train the model?
In the next part, we’ll just barely scratch the surface of data change management strategies.
Topics you’d like me to cover in-depth? Tutorials & implementations that would be helpful? Feel free to comment below 👇 or even to reach out to me on Twitter or LinkedIn.